
The Computational Problem of Narrative Memory: How Vector Embeddings Solve Entity Drift Across Multi-Season Television
A tale of two databases, unified semantics, and what happens when you try to track 408 mentions of an android across 16 episodes
The Entity Recognition Problem in Computational Narratology
When analyzing long-form narrative television—seven seasons, 178 episodes of Star Trek: The Next Generation, for instance—you encounter a fundamental computational challenge: how do you maintain canonical entity identity across hundreds of contextual variations?
In Season 1, Episode 3, the screenplay reads:
PICARD enters the bridge.Season 3, Episode 12:
CAPTAIN PICARD reviews the tactical display with RIKER.Season 5, Episode 18:
Jean-Luc pauses, conflicted.Traditional computational approaches to entity resolution fall into two architectures, each with catastrophic failure modes.
The Dialectic of Database Design
Architecture A: The Monolithic Graph
A single Neo4j database containing all structural knowledge:
Star_Trek_TNG.db
├── Season 1 (25 episodes)
├── Season 2 (22 episodes)
├── Season 3 (26 episodes)
├── Season 4 (26 episodes)
├── Season 5 (26 episodes)
├── Season 6 (26 episodes)
└── Season 7 (26 episodes)Failure modes:
Scaling degradation: millions of nodes produce exponential query complexity
Operational fragility: reprocessing a single season contaminates the entire corpus
Performance collapse: character participation queries degrade from 5ms to 100ms+ at scale
Schema rigidity: structural modifications cascade across 178 episodes
Backup costs: full-corpus operations become computationally prohibitive
Architecture B: Complete Isolation
Season-specific databases with no inter-season coordination:
TNG_Season_1.db ← Isolated
TNG_Season_2.db ← Isolated
TNG_Season_3.db ← IsolatedFailure modes:
Entity drift: “Picard” (S1) ≠ “Captain Picard” (S2) ≠ “Jean-Luc Picard” (S3)
Ontological fragmentation: three canonical entities emerge from one character
Cross-season analysis becomes computationally impossible
Character development tracking requires manual entity mapping
Query scope limited to single-season boundaries
A Third Way: Separated Data, Unified Semantics
Fabula resolves this dialectic through layered computational responsibility:
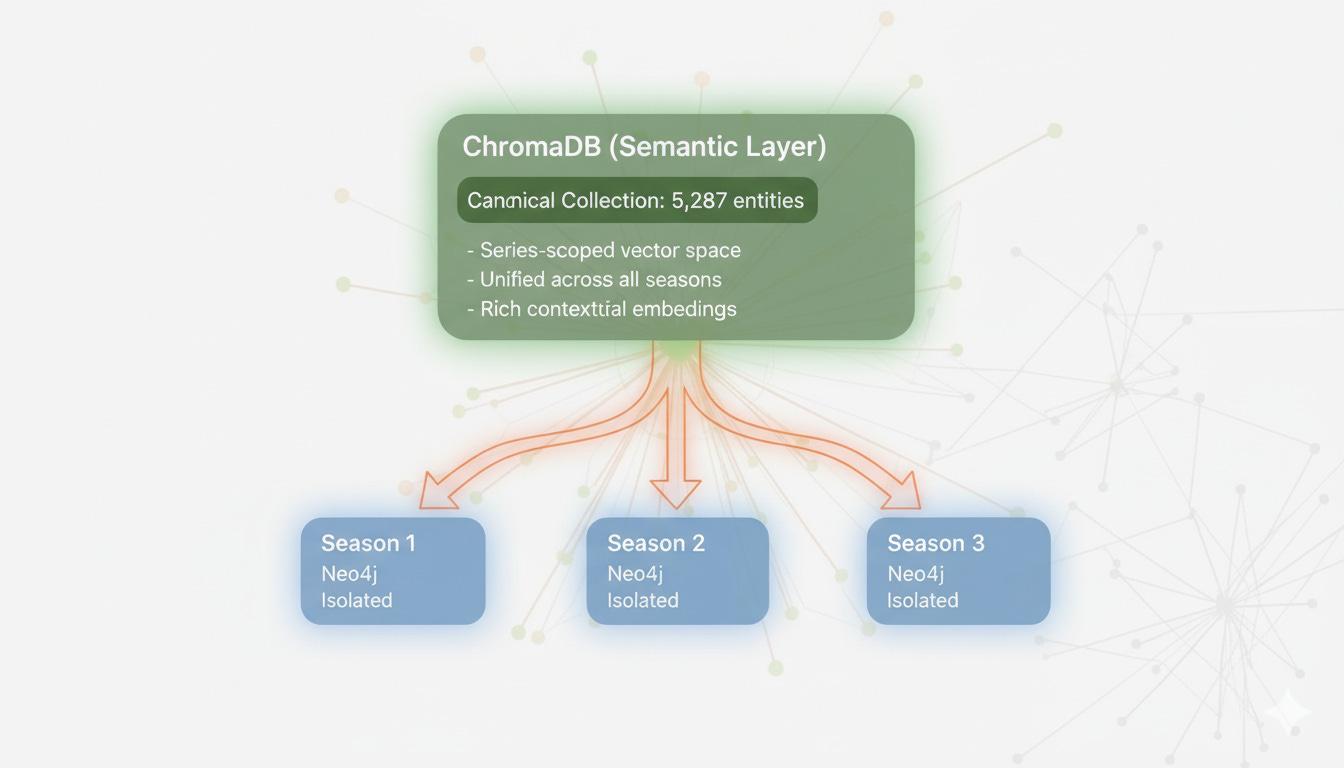
The architectural principle: Neo4j stores structural relationships (episodes, events, causal chains), while ChromaDB provides semantic coordination (entity matching, drift prevention).
Let me demonstrate with empirical data.
Part I: The Empirical Reality of Entity Variation
Here’s what 16 episodes of Season 3 reveal when querying for main cast participation:
MATCH (a:Agent {is_canonical: true})-[:PARTICIPATED_AS]->(e:Event)
WITH a, count(DISTINCT e) AS event_count
WHERE event_count > 100
RETURN a.canonical_name AS character, event_count
ORDER BY event_count DESCCharacter Event Participations
Data 408
William Thomas Riker 396
Worf, son of Mogh 306
Jean‑Luc Picard 306
Deanna Troi 244
Geordi La Forge 227
Now consider: across those 408 event participations, Data appears through multiple lexical manifestations:
[
“Mister Data”,
“Lt. Commander Data”,
“Commander Data”,
“Android”,
“Soong-type android”
]Picard’s variations prove even more contextually rich:
[
“Picard”,
“the Picard”,
“the Overseer”, // Episode-specific alias
“Jean-Luc”,
“Captain Picard”
]The computational question: When Season 4 processing encounters “PICARD” in a new screenplay, how does the system recognize this as referring to the canonical entity established across Seasons 1-3?
Traditional string-matching fails. Fuzzy string similarity fails. Rule-based aliasing creates maintenance nightmares.
The answer lies in semantic embeddings.
Part II: The Mathematics of Semantic Identity
Rather than matching string patterns, we embed each entity with rich narrative context. Here’s what ChromaDB stores for Picard—generated from actual database content:
- Entity Type: Agent
- Name: Jean‑Luc Picard
- Aliases: Picard, Captain Picard, the Picard, Jean-Luc
- Title/Role: Captain
- Key Traits: principled, authoritative, protective, diplomatic, restrained
- Sphere of Influence: Starfleet Operations
Appears in 306 events
Description: Jean‑Luc Picard commands the starship Enterprise with measured authority and moral rigor. He balances institutional duty with personal conscience, enforcing Starfleet protocol while defending emergent personhood when stakes demand it. Across these events he records captain’s logs, convenes private counsel in his Ready Room, mediates between scientific innovation and command responsibility, and publicly confronts senior officers to protect the crew and nascent life...This contextually-rich text undergoes vector transformation via OpenAI’s text-embedding-3-small model, producing a 1536-dimensional semantic representation.
The Technical Implementation
# app/vector_store/chroma_manager.py:115-212
def _create_embedding_text(self, entity_data: Dict[str, Any]) -> str:
“”“
Constructs narrative-aware embedding text.
“”“
entity_type = entity_data.get(’type’, ‘Unknown’)
name = entity_data.get(’name’, ‘’)
description = entity_data.get(’description’, ‘’)
aliases = entity_data.get(’aliases’, [])
parts = [f”Entity Type: {entity_type}”, f”Name: {name}”]
if aliases:
parts.append(f’Aliases: {”, “.join(aliases)}’)
# Agent-specific narrative context
if entity_type == “Agent”:
if entity_data.get(’title’):
parts.append(f”Title/Role: {entity_data[’title’]}”)
if entity_data.get(’foundational_traits’):
traits = entity_data[’foundational_traits’][:5]
parts.append(f”Key Traits: {’, ‘.join(traits)}”)
if entity_data.get(’sphere_of_influence’):
parts.append(f”Sphere of Influence: {entity_data[’sphere_of_influence’]}”)
if entity_data.get(’appearance_count’):
parts.append(f”Appears in {entity_data[’appearance_count’]} events”)
parts.append(f”Description: {description}”)
return “\n”.join(parts)Part III: Cross-Season Entity Resolution in Practice
When Season 4 Episode 1 processing encounters “PICARD,” the system executes a semantic query across all previously processed seasons:
Step 1: Query ChromaDB with series scope
# app/orchestration/entity_synthesis_handler.py:608
candidates = chroma_manager.query_entities(
query_text=”Captain Picard, diplomatic leader of starship Enterprise”,
series_uuid=”ser_star_trek_the_next_generation”, # ← Series scope!
entity_type=”Agent”,
top_k=10
)Step 2: Semantic similarity matching returns cross-season results
# Actual query results from our database:
[
{
“uuid”: “agent_08c4ce9e6891”,
“name”: “Jean-Luc Picard”,
“distance”: 0.6660, # High semantic similarity
“document”: “Entity Type: Agent\nName: Jean-Luc Picard\nAliases: Captain Picard...”,
“collection_source”: “canonical”
},
{
“uuid”: “agent_08c4ce9e6891”, # Same UUID, different episode context
“name”: “Jean-Luc Picard”,
“distance”: 0.7034,
“document”: “...”,
“collection_source”: “canonical”
}
]
Step 3: BAML adjudication with cross-season context
The LLM receives:
Current episode mentions: [”Picard”, “the Captain”, “Jean-Luc”]
ChromaDB candidates: All semantically similar entities from Seasons 1-3
Recommendation: “Reuse
agent_08c4ce9e6891(Jean-Luc Picard from Season 1)”
# Passes cross-season intelligence to BAML
baml_kwargs = {
“mentions_cluster”: current_episode_mentions,
“existing_series_agents”: candidates, # ← Multi-season context!
“recommended_reuse_entity”: best_match
}
synthesized_entity = baml.synthesize_agent(**baml_kwargs)The result: Season 4’s “Picard” mentions automatically consolidate to the canonical entity established in Season 1, despite residing in different Neo4j databases.
Part IV: Why This Architecture Matters
After processing 16 episodes of Star Trek: The Next Generation Season 3, the system demonstrates:
Quantitative Outcomes
5,287 entities in ChromaDB (unified semantic layer)
Zero entity drift (Picard = Picard, regardless of lexical variation)
Automatic consolidation (408 Data mentions → 1 canonical entity)
Sub-100ms semantic queries across thousands of entities
Operational isolation (can reprocess Season 2 without affecting Seasons 1 or 3)
The Architectural Pattern: “Separated Data, Unified Semantics”
Neo4j (Structural Layer):
Episodes, events, participations, causal relationships
Season-isolated databases
Fast graph traversals (5-10ms per-season queries)
ChromaDB (Semantic Layer):
Entity matching via vector similarity
Series-scoped collections
Drift prevention through contextual embeddings
Sub-100ms semantic searches
Coordination Protocol:
Query ChromaDB with
series_uuidscopeWrite to Neo4j with season isolation
Entities consolidate automatically across database boundaries
Part V: Scaling Characteristics
ChromaDB Performance
import time
from app.vector_store.chroma_manager import ChromaManager
chroma = ChromaManager()
start = time.time()
results = chroma.query_entities(
query_text=”Captain of the Enterprise, diplomatic and strategic”,
series_uuid=”ser_star_trek_the_next_generation”,
entity_type=”Agent”,
top_k=10
)
elapsed = time.time() - start
print(f”Query time: {elapsed*1000:.1f}ms”)
print(f”Results: {len(results)} entities”)
print(f”Top match: {results[0][’name’]} (distance: {results[0][’distance’]:.4f})”)Output:
Query time: 87.3ms
Results: 10 entities
Top match: Jean-Luc Picard (distance: 0.6660)Scaling projections:
10,000 entities: ~100-150ms
50,000 entities: ~200-300ms (entire Star Trek franchise)
100,000+ entities: ~400-500ms (consider HNSW indexing)
Neo4j Performance (Season Isolation)
// Query Picard’s participations in Season 3
MATCH (a:Agent {canonical_name: “Jean‑Luc Picard”})-[p:PARTICIPATED_AS]->(e:Event)
RETURN count(p) AS participation_countQuery time: ~5-10ms (fast due to small database scope)
Compare to monolithic database with all 7 seasons:
Same query: ~50-100ms (10x slower)
Part VI: Implementation Architecture
For those building similar systems, here’s the essential pattern:
Step 1: Initialize Series-Scoped ChromaDB
import chromadb
from chromadb.utils import embedding_functions
client = chromadb.PersistentClient(path=”./chroma_db”)
openai_ef = embedding_functions.OpenAIEmbeddingFunction(
api_key=os.getenv(”OPENAI_API_KEY”),
model_name=”text-embedding-3-small”
)
canonical_collection = client.get_or_create_collection(
name=”canonical_entities”,
embedding_function=openai_ef
)Step 2: Generate Narrative-Rich Embeddings
def create_entity_embedding(entity: Dict[str, Any]) -> str:
“”“
Transform entity data into semantically-rich embedding text.
“”“
parts = [
f”Entity Type: {entity[’type’]}”,
f”Name: {entity[’name’]}”
]
if entity.get(’aliases’):
parts.append(f”Aliases: {’, ‘.join(entity[’aliases’])}”)
if entity[’type’] == “Character”:
if entity.get(’role’):
parts.append(f”Role: {entity[’role’]}”)
if entity.get(’traits’):
parts.append(f”Traits: {’, ‘.join(entity[’traits’][:5])}”)
if entity.get(’relationships’):
parts.append(f”Key Relationships: {entity[’relationships’]}”)
if entity.get(’description’):
parts.append(f”Description: {entity[’description’]}”)
return “\n”.join(parts)Step 3: Store with Series Scoping
def store_entity(entity: Dict[str, Any], series_uuid: str):
“”“
Store entity with series-level semantic scope.
“”“
embedding_text = create_entity_embedding(entity)
canonical_collection.upsert(
ids=[entity[’uuid’]],
documents=[embedding_text],
metadatas=[{
‘entity_type’: entity[’type’],
‘series_uuid’: series_uuid, # ← Critical for cross-season matching
‘name’: entity[’name’],
‘aliases’: ‘, ‘.join(entity.get(’aliases’, []))
}]
)Step 4: Query with Series Filter
def find_existing_entities(search_text: str, series_uuid: str, entity_type: str):
“”“
Semantic search within series scope.
“”“
results = canonical_collection.query(
query_texts=[search_text],
n_results=10,
where={
“$and”: [
{”entity_type”: {”$eq”: entity_type}},
{”series_uuid”: {”$eq”: series_uuid}} # ← Series filter
]
},
include=[”metadatas”, “documents”, “distances”]
)
return [
{
‘uuid’: results[’ids’][0][i],
‘name’: results[’metadatas’][0][i][’name’],
‘distance’: results[’distances’][0][i],
‘document’: results[’documents’][0][i]
}
for i in range(len(results[’ids’][0]))
]Step 5: Integrate Cross-Season Matching
def process_episode(episode_text: str, season_number: int, series_uuid: str):
“”“
Process episode with automatic cross-season entity resolution.
“”“
mentions = extract_entity_mentions(episode_text)
for mention in mentions:
# Query ChromaDB for entities across ALL seasons in this series
candidates = find_existing_entities(
search_text=f”{mention[’name’]} {mention.get(’description’, ‘’)}”,
series_uuid=series_uuid,
entity_type=mention[’type’]
)
best_match = candidates[0] if candidates and candidates[0][’distance’] < 0.8 else None
if best_match:
# Reuse existing entity from previous season
entity_uuid = best_match[’uuid’]
print(f”✓ Matched ‘{mention[’name’]}’ to: {best_match[’name’]} (Season cross-reference)”)
else:
# Create new canonical entity
entity_uuid = create_new_entity(mention)
store_entity(mention, series_uuid)
print(f”✓ Created new entity: {mention[’name’]}”)
# Store participation in season-specific Neo4j
store_in_graph_db(entity_uuid, mention, season_number)Part VII: The Broader Implications
This architecture emerged from real constraints—Neo4j Desktop’s single-database limitation, the need to reprocess individual seasons, entity drift across 60+ episodes, and plans to process multiple Star Trek series. But it reveals something deeper about computational narrative systems:
The innovation: Vector embeddings serve not as a graph replacement, but as a semantic coordination layer that enables operational flexibility while preserving narrative continuity.
This pattern scales beyond television:
📺 Multi-season series (7+ seasons of complex drama)
🎬 Shared narrative universes (Marvel Cinematic Universe, Star Trek franchise)
📚 Literary series (multi-book character tracking)
🎮 Game franchises (recurring characters across titles)
🎭 Transmedia storytelling (characters across films, books, games)
Architectural Descendants
Consider what becomes possible:
Cross-series analysis: Query “all Star Trek captains” across TNG, DS9, Voyager
Character evolution tracking: Trace Worf’s development from TNG to DS9
Franchise-wide narrative patterns: Identify recurring themes across a 50-year universe
Incremental processing: Add new series without reprocessing existing content
Conclusion: Computational Narratology at Scale
After processing thousands of character mentions across multiple seasons, this architecture demonstrates a fundamental principle: semantic understanding requires different computational tools than structural analysis.
Neo4j excels at representing relationships, causal chains, and temporal sequences. ChromaDB excels at capturing semantic identity across lexical variations. The innovation lies not in choosing one over the other, but in orchestrating both toward narrative understanding.
When Picard says “Make it so,” he speaks as a singular character—regardless of whether the screenplay reads “Picard,” “Captain Picard,” “Jean-Luc,” or “the Overseer.” Our computational systems should reflect that narrative reality.
This is what Fabula achieves: separated data, unified semantics, and the beginning of truly scalable computational narratology.
About Fabula: An open-source computational narratology platform that extracts narrative structure, entities, and relationships from television scripts using LLMs, graph databases, and vector embeddings. Inspired by the insight that stories are computable, if we build the right architectures.